
Microservices architecture
Problems of older applications
Many older cloud applications use a monolithic architecture. Even though these legacy apps can serve multiple tenants, they’re built as a large and cumbersome set of highly interdependent components. A failure in one component can have devastating impact on another component, resulting in service outages for many or all tenants. Updating these systems requires taking them offline, which limits user access during the upgrade process. The problems of monolithic services are exacerbated when they are deployed in proprietary data centers with limited hardware because the hardware constraints further limit the availability and scalability of the software resources.
Genesys Cloud’s microservices solution
Genesys Cloud solves the problems of monolithic architecture with our use of microservices. With microservices, we solve complex problems with simple, stateless objects. Our microservices architecture also provides virtually unlimited scalability across thousands of servers across multiple, geographically diverse data centers.
Instead of using several tightly coupled components, Genesys Cloud divides its functionality into services, each of which handles a given type of request. Each Genesys Cloud service uses Elastic Load Balancers (ELBs) to distribute work; each grouping contains multiple servers, which dynamically scale based on load. We continuously monitor service-level traffic and optimize the microservices based on usage levels and types of requests.
This diagram illustrates the Genesys Cloud’s major services.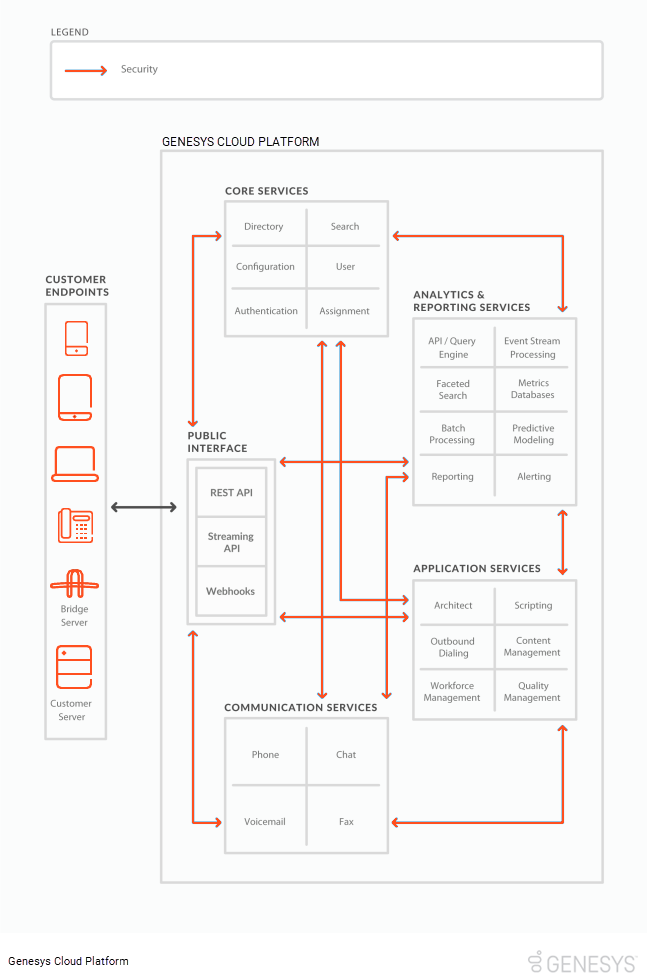
On-demand scaling
Most Genesys Cloud services use an ELB with an auto scaling group (ASG). Genesys Cloud distributes load and monitors groups according to service-specific policies (CPU for compute-intensive services, mean response time for a query service, and so on). When we exceed a threshold policy, the group automatically adds or removes additional resources as needed. For example, if an organization suddenly needs to send a million faxes, the associated microservices automatically scale out to meet the demand without impacting other functionality or other tenants.
Fail-safe processing
Because they operate independently, a problem with one microservice cannot affect the other, which greatly limits the potential for problems. For example, three separate microservices handle voice mail retrieval, outbound faxing, and routing incoming customer calls. If the voice mail retrieval microservice fails, the incoming customer calls microservice continues to function without interruption.
Reliability through recovery
When an individual server fails, the appropriate ELB/ASG detects health check failures or timeouts and detaches the unhealthy component from the load balancer. If this error isn’t transient, additional logic triggers self-healing behavior, where the errant node is stopped and a completely new server is created to take its place. Traffic continues unabated, with other servers in the group seamlessly accommodating the extra work. Genesys Cloud recovers before any user notices a service gap. This recovery process does require a spike in resources, but we have access to ample on-demand bandwidth access through Amazon Web Services (AWS).
Genesys Cloud is built on top of AWS, the undisputed leader in international cloud-based deployments. We work closely with Amazon to test and refine their monitoring and ELB systems.
AWS regions
Genesys Cloud is deployed in multiple, independent AWS regions around the globe. Each region consists of multiple Amazon “Availability Zones,” each of which is comprised of one or more physical data centers. Redundancy is built into the fabric of the system even at this level, with each Availability Zone having separate power, backbone network connectivity, replicated data memory, and (in some cases) physical separation spanning tectonic fault plates. Customer data is replicated across the zones and data centers within a region. The loss of an entire data center would only temporarily reduce capacity; the situation would automatically heal, and it would do so without any data loss. In addition to ensuring data durability, data sovereignty is also an important aspect for a cloud deployment. The Genesys Cloud architecture enables an organization to define its “region of record” to ensure that data doesn’t cross regional boundaries within our infrastructure.
AWS regions for Genesys Cloud Voice deployment
Browsers and mobile clients
In many ways the Genesys Cloud clients mirror the stateless approach used by the microservices. As the browser renders Genesys Cloud, a set of objects is built into the browser memory, including event notifications for data updates. As new information is received by the browser, it updates the objects in memory and then updates the view for the user.
Whenever a user changes their view or starts a new task, existing local data is immediately displayed while a request is made to check for updates. These data requests are shaped to match the available services and optimized to reduce data bandwidth and improve the speed of the client views.
Continual updates
We continually push new code into our production Genesys Cloud system. If a small defect is detected, we simply fix it immediately and push out new versions of the affected services.
Our distributed architecture allows us to release rolling updates without taking the entire system down for maintenance. We use load balancing and techniques like “red-black deployments” to ensure that customers are not adversely affected by our update process. When a new version of a microservice (containing new features or fixes) is available, we create a completely new server image for that service. This image is used to create entirely new servers rather than patching systems in place. As these new servers come online and are determined to be healthy, they are subsequently attached to the load balancer and a small percentage of traffic now begins to be handled by them. Assuming the new servers function as desired, more capacity is added and the old servers (with the previous version of the service) are removed from the load balancer and outstanding requests are drained. Within a matter of minutes, entire fleets of servers providing the functions of a given microservice can be replaced. In addition to making the continuous delivery of service seamless, this provides unparalleled reliability. Avoiding upgrade-in-place reduces brittleness by guaranteeing that the systems we test in our pre-production environments are functionally identical to the systems deployed in production. Additionally, it permits fast rollback to the known-good variant of a microservice in the unlikely case of a new version not functioning as desired.
The independence of microservices and our extensive automated testing and build promotion process allows Genesys to push out bug fixes without the fear of inadvertently breaking something else. What’s more, Genesys can create microservices for new features without impacting existing services. Updates occur while millions of customers are actively using Genesys Cloud.