
Work with exported recordings in AWS S3 bucket
After the AWS S3 recording bulk actions integration is setup, you can export recordings that are in Genesys Cloud in bulk to your AWS S3 bucket. This export can be performed automatically via a QM policy, or explicitly by invoking the recording bulk action API.
This article details the content that is exported to your AWS S3 bucket.
AWS S3 bucket content
Recording files are exported to the AWS S3 bucket into folders with the following structure:
s3://{bucket}/{organizationId}/year={year}/{month={month}/day={day}/hour={hourOfDay}/conversation_id={conversationId}/
| Placeholder | Description |
|---|---|
| {bucket} | The S3 bucket name. |
| {organizationId} | The organization ID. |
| {year} | The year in which the conversation began. |
| {month} | The month during which the conversation began (in digits). |
| {day} | The day during which the conversation began. |
| {hourOfDay} |
The hour during which the conversation began. |
| {conversationId} |
The conversation ID. |
The folder contains all the recording files that are retained during the conversation. Each recording file has one recording, and the name of the file is the recording ID.
Each recording file has a corresponding JSON metadata file. The JSON metadata file name is suffixed with “_metadata.json”.
The metadata can be used to search for the exported recording. For more information, see the Athena+Glue example (an example of a recording search service).
The metadata file is in JSON format with the following schema.
{
“$schema”: “http://json-schema.org/draft-04/schema#”,
“type”: “object”,
“properties”: {
“mediaType”: {
“description”: “Media Type (one of Call, Chat, Email, Message, Screen)”,
“type”: “string”
},
“mediaSubtype”: {
“description”: “The subtype of the recording (one of Trunk, Station, Consult, Screen)”,
“type”: “string”
},
“mediaSubject”: {
“description”: “The subject of the recording”,
“type”: “string”
},
“provider”: {
“description”: “Type of provider for the recording, for example edge”,
“type”: “string”
},
“userIds”: {
“description”: “List of users”,
“type”: “array”,
“items”: [
{
“type”: “string”
}
]
},
“startTime”: {
“description”: “Start time of the recordings”,
“type”: “string”
},
“endTime”: {
“description”: “End time of the recordings”,
“type”: “string”
},
“durationMs”: {
“description”: “Duration of the recording”,
“type”: “integer”
},
“initialDirection”: {
“description”: “Initial direction of the conversation (inbound/outbound)”,
“type”: “string”
},
“aniNormalized”: {
“description”: “ANI”,
“type”: “string”
},
“aniDisplayable”: {
“description”: “ANI in displayable form”,
“type”: “string”
},
“dnisNormalized”: {
“description”: “DNIS”,
“type”: “string”
},
“dnisDisplayable”: {
“description”: “DNIS in displayable form”,
“type”: “string”
},
“queueIds”: {
“description”: “List of queue IDs for the recording”,
“type”: “array”,
“items”: [
{
“type”: “string”
}
]
},
“wrapupCodes”: {
“description”: “Wrap-up codes for the conversation”,
“type”: “array”,
“items”: [
{
“type”: “string”
}
]
},
“organizationId”: {
“description”: “Unique ID for the conversation”,
“type”: “string”
},
“conversationId”: {
“description”: “Unique ID associated with the conversation”,
“type”: “string”
},
“conversationStartTime”: {
“description”: “Conversation’s start time”,
“type”: “string”
},
“conversationEndTime”: {
“description”: “Conversation’s end time”,
“type”: “string”
},
“recordingId”: {
“description”: “Unique ID for the recording”,
“type”: “string”
},
“filePath”: {
“description”: “Original path of the recording”,
“type”: “string”
},
“fileSize”: {
“description”: “Recording file size”,
“type”: “integer”
},
“messageType”: {
“description”: “Type of message platform from which the message originated, e.g., sms, twitter, line, facebook, whatsapp, webmessaging, open, instagram”,
“type”: “string”
},
“languageIds”: {
“description”: “Identifier on the language”,
“type”: “array”,
“items”: [
{
“type”: “string”
}
]
},
“screenInformation”: {
“description”: “Screen specific information, includes the screen ID, X and Y position, resolution information”,
“type”: “object”
}
},
“required”: [
“mediaType”,
“provider”,
“startTime”,
“endTime”,
“durationMs”,
“organizationId”,
“conversationId”,
“conversationStartTime”,
“conversationEndTime”,
“recordingId”,
“filePath”,
“fileSize”
]
}
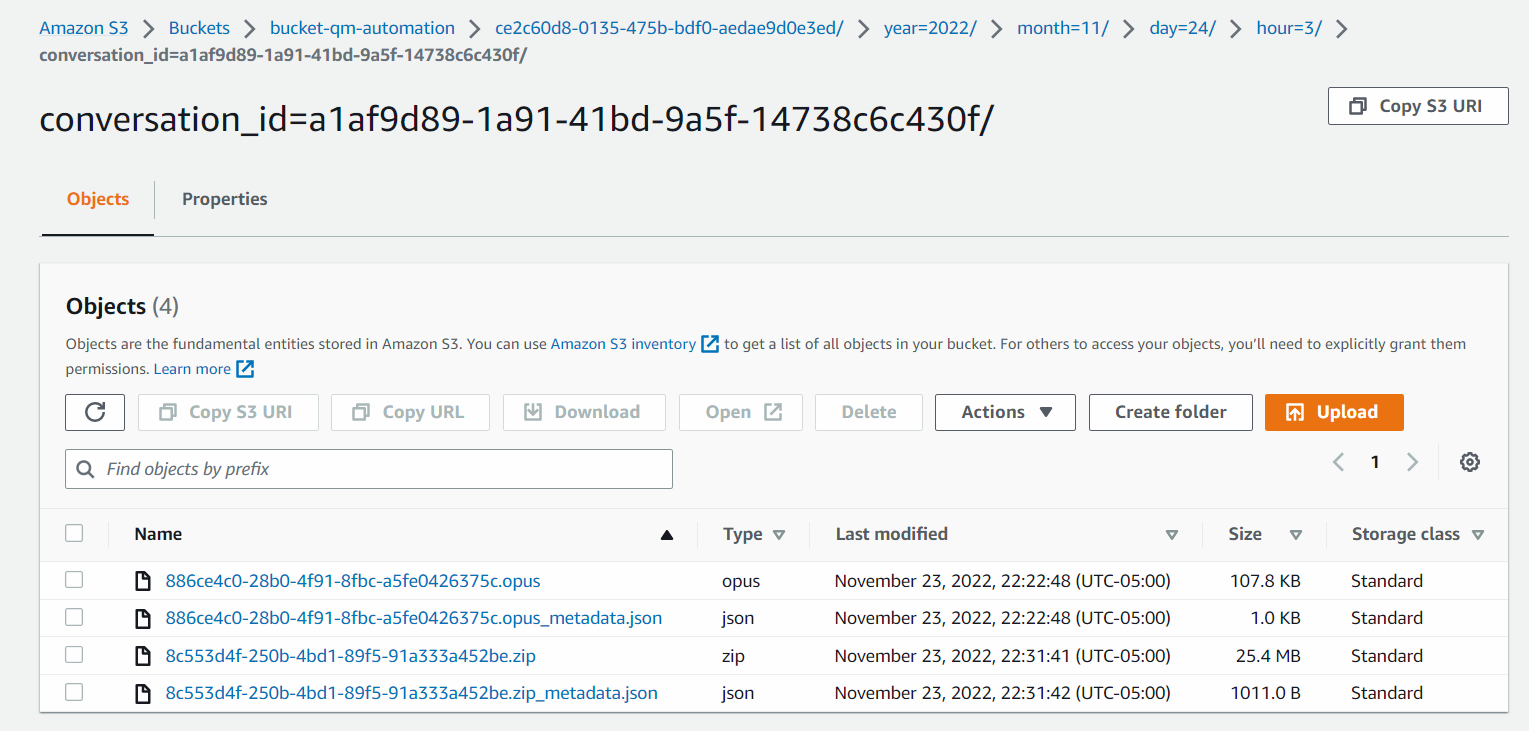
For example, a call conversation with screen recording enabled may have the following folder content.
In the image below, the .opus file is the audio recording file, the .zip file contains the screen recording file, and the .json files are the JSON metadata associated with the respective media files.
Click the image to enlarge.
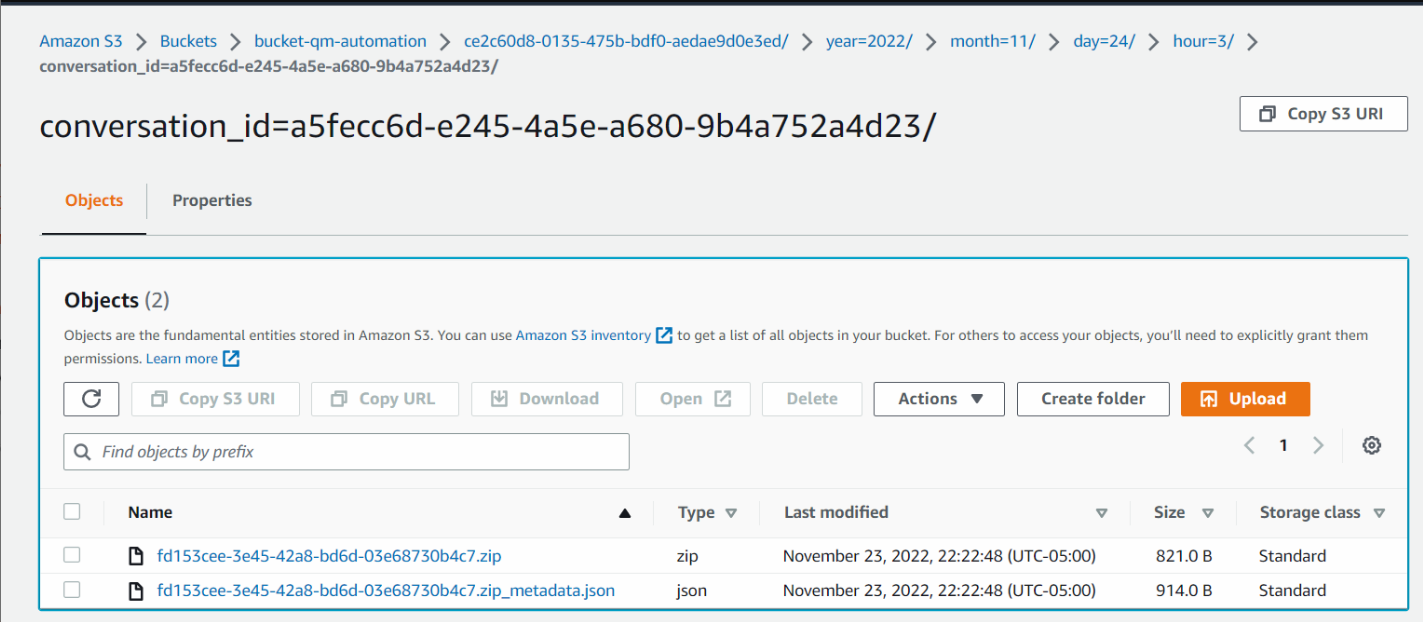
A digital conversation may have the following folder content.
In the image below, the .zip file contains the digital recording file, and the .json file is the corresponding JSON file.
Click the image to enlarge.
Encryption
Your S3 bucket is already configured with AWS S3 Server-Side Encryption (SSE). It may have been enabled with encryption keys that are Amazon S3 managed (SSE-S3), or enabled with the AWS managed keys, or customer-provided keys from the AWS Key Management Service (SSE-KMS).
AWS S3 Server-Side Encryption (SSE) secures the recording files at rest in the S3 bucket. When the files are retrieved from the bucket, AWS automatically decrypts the file content.
If your system includes an additional enabled Recording Export Encryption, you must decrypt the file content yourself after you retrieve the files from the S3 bucket.